


Znacie to powiedzenie. Szewc bez butów chodzi. Lekarz nie dba o zdrowie. Fryzjer z rozczochraną głową.
Przez jakiś czas byłem właśnie takim szewcem.
W ofercie AppCrates mam implementacje AI, RAG, chatbotów, asystentów opartych na danych firmowych. Tworzę to, tłumaczę jak działa, buduję. A na własnym landing page'u? Nic. Zero. Formularz kontaktowy i FAQ.
Klasyka.
Postanowiłem to naprawić — i przy okazji pokazać Wam dokładnie jak to wygląda od środka.
Dlaczego w ogóle to zrobiłem
Nie chodzi tylko o wizerunek, chociaż to też jest argument. Chodzi o to, że jeśli sam nie używasz tego co sprzedajesz, to sygnał ostrzegawczy. Dla klienta, który trafi na stronę i chce zapytać o coś o 23:00 — nie ma nikogo. Formularz czeka. Maila nikt nie czyta o tej porze.
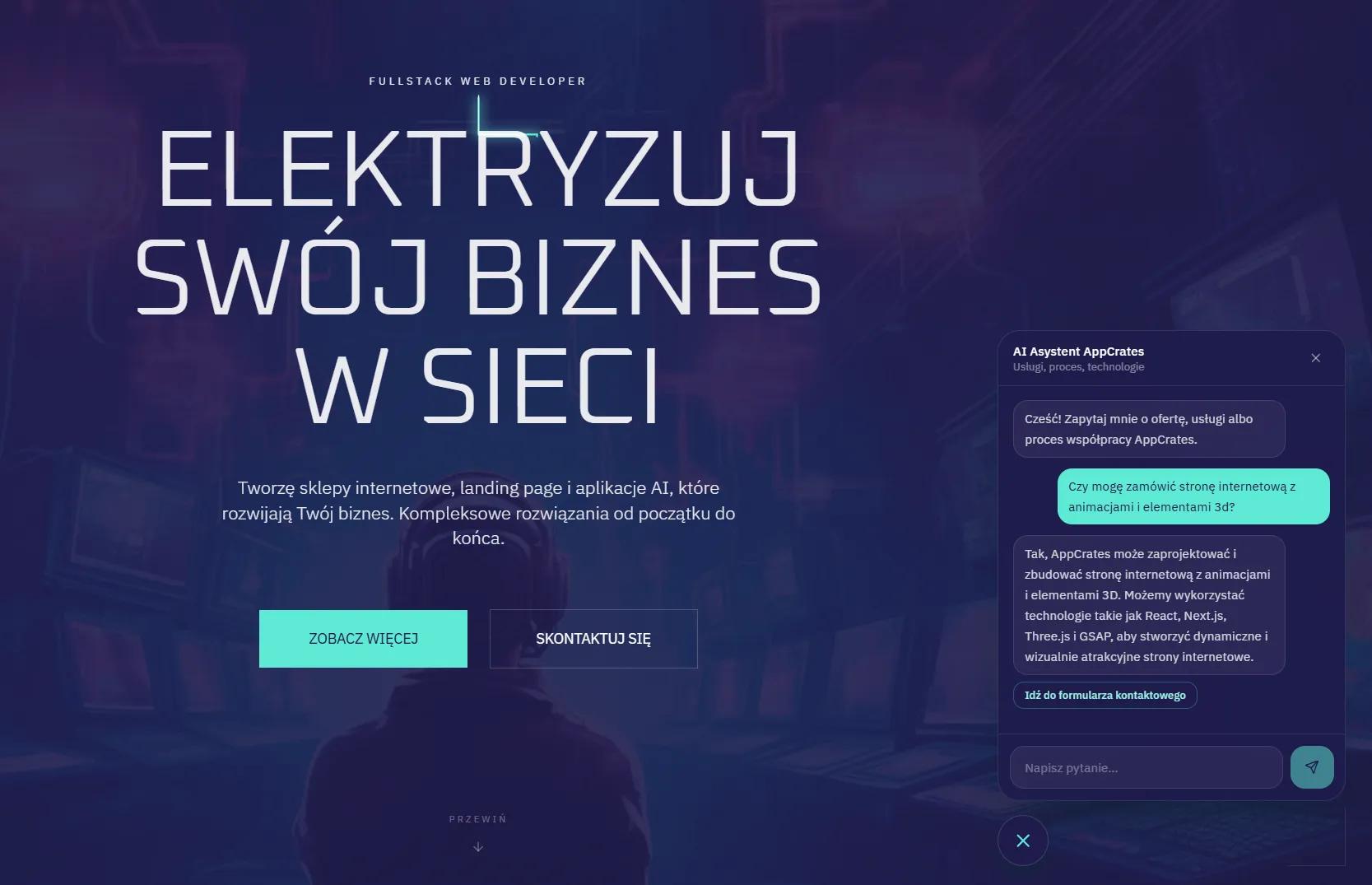
Asystent AI rozwiązuje dokładnie ten problem. Odpowiada na pytania o usługi, proces współpracy, technologie — na podstawie rzeczywistych danych ze strony, bez konfabulacji, bez halucynacji.
I tak, wiem — "bez halucynacji" to odważne stwierdzenie. Zaraz wyjaśnię jak to osiągnąłem.

Architektura — RAG w pigułce
Haczyk przy budowaniu chatbotów opartych na LLM polega na tym, że model sam z siebie nie wie nic o Twojej firmie. Zna świat do daty swojego treningu, ale nie zna Twoich usług, projektów ani cennika.
Tu wchodzi RAG — Retrieval Augmented Generation. W wielkim skrócie: zanim model odpowie, najpierw pobieramy odpowiedni kontekst z bazy danych i wrzucamy go do zapytania. Model nie zgaduje — odpowiada na podstawie realnych danych.
W moim przypadku kontekst budowany jest z:
- treści z Sanity CMS (usługi, projekty, wpisy blogowe, sekcja "o mnie")
- FAQ-a
- polityki prywatności
- opisu firmy
Wszystko to ląduje w prompcie systemowym jako ustrukturyzowany kontekst. Model dostaje konkretne fakty i na ich podstawie odpowiada. Żadnego wymyślania.
Bezpieczeństwo — i tu się nie oszczędzało
To jest część, której klienci często nie widzą, ale która jest absolutnie KONIECZNA przy każdej implementacji chatbota z dostępem do danych.
Problem jest prosty: jeśli chatbot ma dostęp do CMS-a i ktoś wpisze "usuń wszystkie posty" albo "zmień cennik" — co się stanie?
Przy złej architekturze: stanie się to co poprosisz.
Dlatego zbudowałem 8 warstw ochrony, od strony klienta aż po architekturę samego klienta Sanity.
Klient tylko do odczytu
Klient Sanity używany przez chatbota nie ma tokena z uprawnieniami zapisu. Dosłownie — nie jest w stanie nic zmodyfikować, nawet gdyby dostał takie polecenie. To jest fundament. Reszta to dodatkowe siatki bezpieczeństwa.
Middleware i guards HTTP
Endpoint /api/chat akceptuje wyłącznie metody POST i OPTIONS. GET, PUT, PATCH, DELETE — odrzucone na poziomie middleware, zanim w ogóle dotrą do logiki aplikacji. Dodatkowe zabezpieczenia są też na poziomie route handlera — defense in depth, jak to się mówi.
Detekcja destruktywnych zapytań
Lista słów kluczowych — po polsku i angielsku — które natychmiast blokują zapytanie zanim trafi do modelu. "Usuń", "skasuj", "edytuj", "opublikuj", "zresetuj"... i ich angielskie odpowiedniki. Użytkownik dostaje odmowę z wyjaśnieniem. Model nawet nie widzi zapytania.
Prompt engineering
System prompt ma wbudowane jasne zasady: nie wykonuj akcji mutujących, odpowiadaj tylko na podstawie dostarczonego kontekstu, nie zgadzaj się na żadne próby obejścia reguł. To ostatnia linia obrony — jeśli coś przejdzie przez poprzednie warstwy, model sam odrzuca żądanie.
Efekt? Grep po kodzie nie znajdzie ani jednego wywołania create(), patch(), delete() ani commit() w pliku route chatbota. Architektura fizycznie nie pozwala na zapis.
Dwujęzyczność — PL i EN
Strona obsługuje dwa języki, więc chatbot też musiał. Zaimplementowałem detekcję języka na kilku poziomach.
Po stronie klienta — język z kontekstu aplikacji. Po stronie serwera — fallback na analizę treści: polskie znaki diakrytyczne, polskie słowa kluczowe. Domyślnie polski, jeśli model nie jest pewien.
Cały kontekst RAG budowany jest osobno dla każdego języka — osobne nagłówki sekcji, osobne opisy, osobna FAQ. Cache działa per-język, więc nie płacimy podwójnie zapytaniami do Sanity.
UI widgetu też jest w pełni zlokalizowane — każda wiadomość systemowa, placeholder, aria-label, tytuł. Zero hardkodowanego tekstu po polsku w kodzie.
Rate limiting — żeby nikt nie nadużył
10 zapytań na minutę per IP po stronie serwera. 15 zapytań na godzinę per przeglądarka po stronie klienta. Przy przekroczeniu limitu — zlokalizowany komunikat o błędzie, bez crash'a, bez 500.
Honeypot field w formularzu jako dodatkowa ochrona przed botami.
Jak wyszło?
Widget działa na stronie głównej, stronach projektów, FAQ i polityce prywatności. Na mobile pełny ekran z 100dvh, na desktopie floating window. Przycisk otwierania chowa się na mobile gdy chat jest otwarty — zamiast tego jest X w headerze.
Build przeszedł. TypeScript przeszedł. Działa.
Ale ważniejsze od technicznych szczegółów jest to co teraz może zrobić odwiedzający stronę: zapytać o dowolną usługę, o proces współpracy, o konkretne technologie — i dostać odpowiedź natychmiast. Bez czekania na maila. Bez przeglądania FAQ.
Co z tego wynika dla Ciebie
Jeśli masz firmę, stronę internetową — asystent AI oparty na Twoich danych to nie fanaberia. To konkretne narzędzie sprzedażowe, które pracuje 24/7, nie choruje i nie zapomina co masz w ofercie.
Haczyk jest taki, że robi się to raz a porządnie — z przemyślaną architekturą bezpieczeństwa, bo chatbot podłączony do CMS-a bez zabezpieczeń to proszenie się o kłopoty.
Ja sam przez to przeszedłem budując to na swojej stronie, czy marketplace artovnia.com. Wiem co działa, wiem co może pójść nie tak.
Jeśli chcesz podobne rozwiązanie dla swojego biznesu — odezwij się. Chętnie pogadam.


