

Mówi się, że jak coś działa, to nie ma sensu tego ruszać.
I po części jest to prawda.
Haczyk polega na tym, że są projekty, w których „działa” oznacza tylko tyle, że strona otwiera się w przeglądarce. A to jeszcze nie znaczy, że działa dobrze biznesowo, dobrze architektonicznie i dobrze pod SEO.
Przez długi czas AppCrates działał jako klasyczne Vite + React. Lokalnie? Bajka. Szybki HMR, prosty setup, zero zbędnej filozofii. Do prototypowania albo do aplikacji, gdzie SEO nikogo specjalnie nie obchodzi, Vite jest naprawdę świetny.
Tylko że AppCrates nie jest panelem admina ani apką „po zalogowaniu”. To strona usługowa. Ma zbierać ruch, pokazywać ofertę, projekty, artykuły, odpowiadać na pytania klientów i być widoczna w Google.
I właśnie tutaj zaczęły wychodzić problemy, których nie dało się już zamiatać pod dywan.
Największy był bardzo prosty:
Googlebot widział prawie pusty HTML.
Vite było świetne... dopóki nie przestało wystarczać
W teorii wszyscy wiedzą, że Google „potrafi” renderować JavaScript.
W praktyce? Różnie z tym bywa.
To nie jest tak, że bot zawsze odpali wszystko idealnie, poczeka grzecznie na dane z API, zrenderuje komponenty i jeszcze poprawnie zinterpretuje metadata. Czasem tak. Czasem nie. Czasem z opóźnieniem. Czasem połowicznie.
A jeśli budujesz bloga, stronę usługową albo landingi pod SEO, to „czasem” to za mało.
U mnie wyglądało to mniej więcej tak:
<!DOCTYPE html>
<html>
<head>
<title>AppCrates</title>
</head>
<body>
<div id="root"></div>
<script src="/assets/index-abc123.js"></script>
</body>
</html>Czyli w uproszczeniu:
- użytkownik z JS widzi stronę,
- bot na starcie widzi pustą skorupę,
- cała treść pojawia się dopiero po odpaleniu aplikacji.
I teraz pytanie brzmi: czy da się z tym żyć?
Da się.
Ale tylko do pewnego momentu.
Pierwszy plaster: edge function dla crawlerów
Zanim zrobiłem pełną migrację, próbowałem to obejść.
Na Netlify działała dedykowana edge function social-crawler.js, która wykrywała boty po User-Agent i serwowała im prerenderowany HTML zamiast pustego shella.
Czy to działało? Tak.
Czy było eleganckie? Niespecjalnie.
To był klasyczny przykład rozwiązania, które pomaga, ale jednocześnie zaczyna żyć własnym życiem. Trzeba było utrzymywać osobną warstwę logiki tylko po to, żeby crawler dostał coś, co normalnie powinien dostać z samej aplikacji.
Każda nowa podstrona to dodatkowa robota.
Każda zmiana HTML to ryzyko, że bot zobaczy coś innego niż użytkownik.
Każda rozbudowa projektu dokładała kolejną warstwę „tymczasowości”, która robiła się coraz mniej tymczasowa.
W pewnym momencie zacząłem mieć wrażenie, że buduję osobny system SEO obok aplikacji.
A to jest moment, w którym wiadomo, że architektura zaczyna iść w złą stronę.
Dlaczego finalnie padło na Next.js
To nie była decyzja pod tytułem: „wszyscy robią Nexta, to ja też”.
Ja nie migrowałem dlatego, że framework jest modny. Migrowałem dlatego, że SPA przestało pasować do typu projektu.
Rozważane były też Astro, Tankstack.
Potrzebowałem kilku rzeczy, które w tym układzie były po prostu KONIECZNE.
1. Bot ma dostać gotowy HTML od razu
Bez kombinowania.
Bez edge function udającej SSR.
Bez liczenia na to, że może Google sobie to dorysuje później.
Next.js z App Routerem daje mi pełny HTML na pierwszym requestcie. I dokładnie o to chodziło.
2. Metadata i JSON-LD miały być częścią aplikacji, a nie doklejką
W SPA metadane bardzo często są półśrodkiem:
- statyczne w
index.html, - albo zarządzane client-side,
- albo łatane jakąś dodatkową warstwą.
To działa... dopóki nie chcesz robić tego porządnie dla dynamicznych treści z CMS-a.
W Next.js każda trasa może mieć własne generateMetadata, działa to po stronie serwera i może pobrać dane asynchronicznie z Sanity. Czyli dokładnie tak, jak powinno to wyglądać od początku.
3. Cache w końcu zaczął mieć sens
W starej wersji zapytania do Sanity leciały praktycznie przy każdej wizycie. Bez sensownej centralizacji, bez spójnej strategii.
Po migracji cache siedzi w warstwie danych, a nie w pięciu przypadkowych miejscach aplikacji. I nagle całość zaczyna być przewidywalna.
Jak to wygląda po migracji
Routing w App Routerze
Nowa struktura opiera się o src/app, więc routing w końcu jest prosty i naturalny:
src/app/
page.tsx → /
about-me/page.tsx → /about-me
blog/page.tsx → /blog
blog/[slug]/page.tsx → /blog/:slug
project/[slug]/page.tsx → /project/:slug
uslugi/[slug]/page.tsx → /uslugi/:slug
faq/page.tsx → /faq
privacy-policy/page.tsx → /privacy-policy
robots.ts → /robots.txt
sitemap.ts → /sitemap.xml
not-found.tsx → 404I to jest jedna z tych rzeczy, które po migracji docenia się najbardziej.
Nie ma kombinowania, nie ma dziwnej synchronizacji, nie ma trzymania połowy logiki poza aplikacją. robots.txt i sitemap.xml są generowane natywnie, a nie klejone gdzieś z boku.
Server Components i Client Components
To był jeden z ważniejszych elementów całej przebudowy.
Zasada była prosta:
To, co ma zobaczyć robot, renderuje serwer.
To, co ma poczuć użytkownik, może obsłużyć klient.
Po stronie serwera wylądowały:
- pobieranie danych z Sanity CMS,
- metadata:
title,description, Open Graph, canonicale, - structured data / JSON-LD,
- render treści blogowych,
- rzeczy, które mają być obecne w HTML od razu.
Po stronie klienta zostały:
- animacje i efekty wizualne,
- formularze,
- cookie consent,
- analytics,
- FAQ accordiony, trackery widoku i cała interakcja.
Brzmi banalnie, ale dopiero po zrobieniu takiego podziału widać, ile wcześniej rzeczy było wrzuconych „gdzie popadnie”.
Warstwa danych i cache
Zamiast ustawiać cache osobno na każdej trasie, scentralizowałem to w fetcherze Sanity:
async function fetchSanity<T>(
query: string,
params?: Record<string, unknown>
): Promise<T> {
return client.fetch(query, params || {}, {
next: { revalidate: 3600 },
});
}Czyli w wielkim skrócie:
- dane z Sanity są cache’owane przez godzinę,
- cache działa na poziomie danych,
- nie muszę rozwiązywać tego samego problemu osobno w każdym miejscu aplikacji.
I to był dobry ruch, szczególnie że część tras i tak jest dynamiczna.
Cookies, język i świadomy kompromis
AppCrates obsługuje język przez cookies.
A to ma konkretną konsekwencję: jeśli trasa czyta cookies(), Next traktuje ją jako dynamiczną. Czyli odpada pełne statyczne generowanie całej strony w klasycznym sensie.
Dla niektórych to od razu brzmi jak wada.
Dla mnie niekoniecznie.
Bo pytanie nie brzmi: „czy da się to zrobić bardziej statycznie?”.
Pytanie brzmi: „czy użytkownik dostaje poprawny język od razu, bez migania interfejsu po hydracji?”.
U mnie odpowiedź brzmi: tak.
Więc trade-off jest świadomy:
- minus: mniej statyczności na poziomie tras,
- plus: poprawny język na pierwszym renderze.
W takim modelu to cache danych robi ciężką robotę. I to w zupełności wystarcza.
Netlify: problem, którego na początku prawie nie zauważyłem
Sama migracja kodu to była tylko połowa roboty.
Druga połowa to hosting.
I tutaj wyszło coś, co łatwo przegapić: można mieć poprawnie przepisany projekt na Next.js, a produkcja i tak dalej będzie zachowywać się jak stare SPA.
Dokładnie tak było u mnie.
AppCrates siedział na Netlify skonfigurowanym wcześniej pod Vite:
- publish directory wskazywał na
dist, - część ustawień żyła w panelu Netlify,
- były aktywne stare redirecty typu SPA fallback.
Efekt?
Kod już był nextowy, ale hosting dalej żył mentalnie w świecie Vite.
Musiałem więc ogarnąć osobno:
- przełączenie
netlify.tomlnanpm run build:next, - odpięcie starego
dist, - usunięcie redirectów pod SPA,
- wyłączenie edge function
social-crawler, - zostawienie AI edge function pod
/api/ai-generate, bo ona akurat nadal miała sens.
I z tego płynie bardzo prosty wniosek:
Migracja frameworka i migracja hostingu to NIE jest to samo zadanie.
Można mieć dobry kod i zły deploy.
I wtedy wszystko wygląda tak, jakby aplikacja dalej była starym SPA.
Co po drodze się wysypało
Nie ma migracji bez zgrzytów. U mnie też kilka rzeczy po drodze dało o sobie znać.
1. Stan przejściowy w repo
Przez jakiś czas w repo żyły obok siebie:
- nowe trasy Next,
- stare pliki z Vite,
- katalogi legacy,
- komponenty, które już niby były przeniesione, ale jeszcze nie do końca było wiadomo, czy można je usunąć.
Czyli klasyczny stan: „działa, ale nikt poza autorem nie wie, co jest źródłem prawdy”.
Finalnie skończyło się pełnym cleanupem i dokumentacją. I dobrze, bo zostawienie tego na później tylko dokłada długu technicznego.
2. Pierwszy render bez widocznego tekstu
To był jeden z bardziej irytujących problemów.
Lokalnie strona ładowała style, ale część tekstu była niewidoczna do momentu odświeżenia albo końca hydracji. Winne były animacje ze stanem startowym, które ukrywały content.
Czyli klasyka:
opacity: 0,- wejście po hydracji,
- a treść above-the-fold znika jak kamfora.
Naprawa była prosta, ale ważna:
- zmiana initial state animacji,
- dopilnowanie, żeby kluczowa treść była widoczna już w HTML z serwera,
- usunięcie efektów, które robiły ładne demo, ale psuły pierwszy render.
Ładne animacje są fajne.
Ale nie wtedy, kiedy chowają to, po co użytkownik w ogóle wszedł na stronę.
3. Windows i jego „uroki”
Były też problemy totalnie nieaplikacyjne:
- wiszące procesy Node,
- zajęty port
3000, .next/tracezablokowany przez system,- błędy
EADDRINUSEiEPERM.
Czyli nie bug w kodzie, tylko środowisko, które mówi: „dziś sobie nie popracujesz”.
Standardowo pomagało:
- sprawdzenie procesu na porcie,
- albo po prostu brutalne
taskkill /F /IM node.exe.
4. Tymczasowo wyłączony TypeScript i ESLint podczas builda
Na ten moment next.config.ts ma tymczasowo:
typescript
eslint: { ignoreDuringBuilds: true },
typescript: { ignoreBuildErrors: true }
I nie, nie dlatego, że „typy są nieważne”.
Powód jest dużo bardziej przyziemny: stare pliki legacy po Vite miały historyczne błędy, które nie dotyczyły już nowej architektury, ale potrafiły blokować build.
Produkcja jest zielona.
Natomiast przywrócenie pełnej rygorystyki typów i lintera to osobny etap cleanupu, a nie coś, co chciałem mieszać z samą migracją.
I moim zdaniem to jest ważne rozróżnienie.
Nie wszystko trzeba robić naraz.
Co ta migracja realnie dała
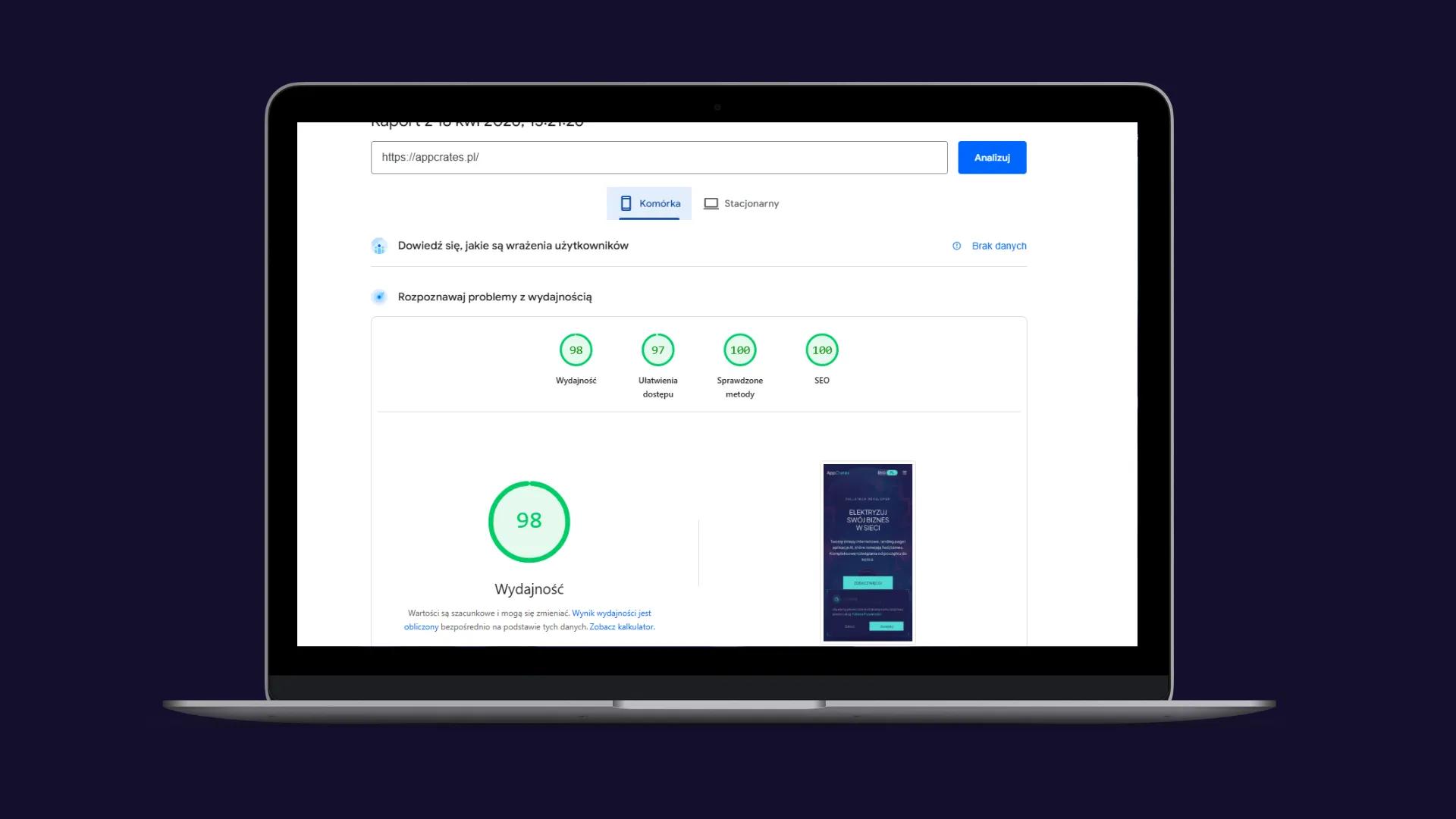
SEO w końcu przestało być sztuką walki
Największy zysk jest bardzo prosty:
Googlebot dostaje pełny HTML na wejściu.
Bez odpalania JS.
Bez czekania.
Bez edge workaroundów.
Bez zgadywania, czy crawler zobaczy to samo co użytkownik.
Do tego każda podstrona ma własne metadata generowane po stronie serwera, na bazie danych z Sanity. Czyli nie mam już jednego globalnego „AppCrates” na wszystko, tylko faktycznie sensowną warstwę SEO per route.
Structured data przestało być doklejką
JSON-LD nie jest już czymś, co trzeba gdzieś „doinicjalizować” po stronie klienta. Ląduje w renderowanym HTML tam, gdzie powinno.
Mała rzecz? Niby tak.
Ale właśnie z takich małych rzeczy robi się porządna architektura.
Projekt zaczął skalować się normalnie
Nowa usługa?
Nowy typ wpisu?
Nowa podstrona z CMS-a?
W App Routerze wszystko ma swoje naturalne miejsce. Nie trzeba dopisywać crawlerowych wyjątków, ręcznie ogarniać kolejnych meta hacków i pilnować, żeby pięć różnych warstw mówiło jednym głosem.
Lepsza analityka
Przy okazji migracji rozbudowałem też warstwę analytics.
Nie skończyło się na samych pageviewach. Doszły eventy, które faktycznie coś mówią o jakości ruchu:
- wejście w obszar formularza,
- pierwsza interakcja,
- kliknięcie w telefon lub email,
- wysłanie formularza,
- wygenerowanie leada.
I nagle widać nie tylko „ile osób weszło”, ale też „czy ten ruch ma jakąkolwiek wartość”.
A to jest zupełnie inna rozmowa.
Czego się nauczyłem po tej migracji
1. Nie przepisywać designu przy okazji migracji technicznej
To jest bardzo kuszące: skoro już ruszasz architekturę, to może od razu nowy layout, nowy design system, nowe sekcje, nowe wszystko.
No nie.
To prosty sposób, żeby rozwalić zakres projektu i ugrzęznąć na tygodnie.
U mnie warstwa wizualna została praktycznie ta sama. src/components/new/* dalej robiło robotę. Zmienił się silnik, nie karoseria.
I tak było rozsądniej.
2. Hosting jest częścią migracji, a nie dodatkiem
Jeśli ktoś migruje framework i zakłada, że deploy „sam się ogarnie”, to bardzo szybko zderzy się ze ścianą.
Kod to jedno.
Infrastruktura to drugie.
I obie rzeczy trzeba zamknąć razem.
3. Dynamiczne renderowanie nie jest porażką
Mam wrażenie, że czasem ludzie traktują pełną statyczność jak religię.
A przecież jeśli aplikacja potrzebuje kontekstu użytkownika — języka, sesji, personalizacji — to dynamiczny render może być po prostu właściwym wyborem.
Nie chodzi o to, żeby wszystko na siłę wypłaszczyć do statyka.
Chodzi o to, żeby całość była sensowna.
4. Cleanup to nie jest dodatek „na kiedyś”
Jeżeli po migracji zostawiasz pół repo w trybie „legacy, ale nie ruszajmy”, to ten bałagan wróci do Ciebie przy kolejnym tasku.
Nie od razu.
Ale wróci.
5. Dokumentacja najbardziej przydaje się chwilę po wszystkim
Nie w trakcie.
Nie dzień po deployu.
Tylko dwa tygodnie później, kiedy wracasz do projektu i zastanawiasz się:
- co jest źródłem prawdy,
- co zostało po starym setupie,
- dlaczego produkcja robi coś inaczej niż local.
Wtedy dobra dokumentacja ratuje masę czasu.
Podsumowanie
Migracja AppCrates z Vite do Next.js App Routera nie była zmianą „narzędzia dla zasady”.
To była zmiana modelu działania całej strony.
Ze świata SPA, gdzie SEO trzeba było podpierać obejściami, przeszedłem do architektury, w której rendering, metadata i warstwa danych są domyślnie prowadzone po stronie serwera.
I właśnie to robi największą różnicę.
Jeżeli budujesz:
- stronę usługową,
- bloga,
- portfolio,
- albo jakikolwiek projekt, który ma być znajdowany w wyszukiwarce,
to w pewnym momencie klasyczne SPA zaczyna wymagać coraz większej liczby plastrów. A potem nagle orientujesz się, że więcej czasu spędzasz na obchodzeniu ograniczeń architektury niż na rozwijaniu samego produktu.
I wtedy warto zadać sobie proste pytanie:
czy dalej chcesz to łatać, czy po prostu postawić to na właściwych fundamentach?
Ja wybrałem drugą opcję.
I szczerze?
Dużo za późno.
Zajmuję się migracjami aplikacji frontendowych do Next.js App Routera — razem z SEO, warstwą danych, hostingiem i cleanupem legacy kodu. Jeśli masz projekt, który zaczyna dusić się w starym SPA, napisz do mnie.


